

BI-as-Code and the New Era of GenBI


This is Part 2 of a 3 part blog series guest written by Simon Späti. See Part 1: The Rise of the Declarative Data Stack, and Part 3: Designing of a Declarative Data Stack in Practice.
Imagine creating business dashboards by simply describing what you want to see. No more clicking through complex interfaces or writing SQL queries - just have a conversation with AI about your data needs. This is the promise of Generative Business Intelligence (GenBI).
At its core, GenBI delivers an unreasonably effective human interface, where we iterate quickly, based on BI-as-Code. A simplified version looks like this:

But what makes this possible? The key lies in the declarative BI stack as discussed in Part 1 - where dashboards and metrics are defined as code (like covid_dashboard.yaml) rather than hidden behind graphical user interfaces. The declarative approach gives AI models the context they can understand and work with: structured definitions of business metrics, relationships between facts and dimensions, and visualizations.
In this article, we want to explore the possibilities of GenBI today.
Understanding GenBI
Generative business intelligence changes how people interact with data, enabling AI-driven analytics. By harnessing the power of Generative AI, GenBI makes analytics more accessible through new human interaction methods. Generative BI enables these use cases, from creating dashboards to natural language querying (typing or talking), all the way down to the data model generation if you only have the source tables. We explain the model from a top-down, conceptual idea of what we need, and we generate dashboards, metrics, data models (snowflake/star schema, relationships, joins, even grains), entities, or even data warehouse architectures.
A key aspect of GenBI is its declarative nature, as we discussed in the Declarative Data Stack. Whether the entire stack or not, one of the most critical layers is the Metrics Layer. Generative AI needs context to understand the data model and the company's business. The metrics layer and its semantics (also called semantic layer) are relevant for this process, as the metrics hold the semantic understanding.
One step further: Data modeling languages such as LookML, MDX, MAQL, Malloy language, or SQL are critical. These languages allow humans to describe and model our metrics and KPIs, from which AI models can learn. They are expressive and declarative and define the company's business logic.
To illustrate how GenBI leverages a declarative dashboard, let's see how Al can automatically add a new measure for average fare cost per mile to our existing metrics within the text editor:
In summary, combining AI models with BI tools allows business users to query data, generate reports, and derive insights using conversational language, making data analytics more accessible.
Is GenBI the new Self-Service BI?
Self-service BI has been around for a while, trying to enable business users to create dashboards and reports. But that transition has always been hard, and without SQL or even Python skills to wrangle and clean your data, it's hard. I think GenBI is the next attempt for Self-Service BI, which is very promising.
Evolution from Traditional BI to GenBI
Before we discuss GenAI, let's understand the difference between today's BI and GenBI.
To grasp that, let's quickly follow the evolution of SQL, and how it shaped the BI tools. From traditional data marts and materialized views queried directly by the BI tool, we've built data warehouses, lakes, or lakehouses with tools such as dbt and data warehouse automation tools. Sometimes, we added an OLAP cube if we needed fast response times, typically modeled as OBT tables or wide denormalized tables.
In all of the different ways, SQL has been at the heart, even more with complex data pipelines and semantic layers. Even Large Language Models (LLMs) made it into SQL statements.
With GenBI, this will not change as the BI tools need to execute SQL at the end of the day. But what is important is that the metrics and the SQL statement are declarative stored. Therefore, it might be easier to work with YAML to maintain complex definitions, at least until we extend the SQL syntax for analytics.
How GenAI Powers BI and compare to GenBI
The main difference between traditional BI and GenBI is understanding the semantics behind SQL with AI. What does that mean?
SQL is a declarative language; therefore, the AI model can learn from the queries. If we feed it with more data, such as the metrics in a metrics layer as part of the BI tool, and if available, the data model (DDL), the model will have a semantic understanding of queries. If you have a declarative dashboard tool such as Rill, you can train the model on the dashboards so it learns how we create them within the company, too.
GenAI has an LLM trained on our business intelligence artifacts. In return, it can generate visualizations in the form of dashboards and metrics in the form of SQL aggregation for us.
The other part of GenBI is what we use every day. With the rise of ChatGPT and similar tools, we can interface with our tools in a more human-like manner. Instead of writing SQL, we can speak or write natural language to query data or present it in a dashboard, compared to hand-crafting. These are two use cases, but the applications are endless, and new ways of interaction arise every day.
Ultimately, if we talk about GenBI, we must mention GenAI as the driving force and integrate AI technologies with BI tools and data sources. GenAI is a broad term encompassing all generative AI technologies, while GenBI is a specialized application of GenAI focused on business intelligence.
What is Semantic SQL?
In this context, it might be helpful to understand semantic SQL. It represents business concepts in SQL queries, making complex data accessible without requiring technical database knowledge. It gives business users direct access to data through simplified terminology. Abstract Syntax Threes (AST) can be used for visualization and deciphering the relationships, dependencies, and connections behind the queries. These enable further features like automated dependency tracking and cross-dialect compatibility.
General Knowledge LLM speaks GenBI
OpenAI has trained LLMs with millions of StackOverflow posts, so you don't have to. Prompting an AI to generate SQL statements for common queries has become straightforward. They have been trained on the usual Stripe and Shopify data models and columns. For example, related GenBI implementations, such as GitHub's Copilot, offer similar capabilities and generate SQL and code within your GitHub environment. How we do that with BI is discovered in a later chapter, "GenBI in action".
BI-as-Code: The Foundation of GenBI
We've gone through a long evolution of mouse-clicking first dashboard tools, where everything you define lives within the UI. These tools produce unwieldy exports with hard-coded IDs and visual coordinates, often spanning thousands of lines of XML/JSON that are hard to version or modify systematically.
.jpeg)
The benefits of each are clearly visible:
- Graphical and traditional BI approach: Initially fast but slow with iterations. With manual changes, error prone.
- Code-First Approach: Scales well with complexity. Works well with teams.
- GenBI: Instant interactions through general knowledge LLMs. The best of both worlds makes it more approachable for businesses and users with the natural interface.
Benefits of Code-First Analytics
Today, newer code-first approaches let you define dashboards declaratively, bringing all the advantages of the Declarative Data Stack: automation, versioning, and separation of business logic from implementation. This approach offers the best of both worlds – an intuitive UI for design while producing clean YAML definitions that can be versioned and bulk-modified with search + replace across all dashboards or using AI within your editor.
Code-first enables a smaller data team to do more. Think of the Ruby on Rails developer, who does end-to-end from changing the database theme to the front of the app. Instead of multiple people understanding every little column of a Shopify database model, we can prompt the BI model that has been trained on the physical data tables and potentially 100 or reference implementations from GitHub to generate a "dashboard for the sum of orders per month". This will not be 100% accurate, but you might get 80% of the work within a very short time.
Instead of generating just the dashboard, it could create a central metrics layer repository to enhance versioning and maintainability, which would improve governance.
But beyond maintainability - it creates a semantic foundation that AI can understand. When dashboards are defined in code, they explicitly declare:
- The metrics being visualized and how they're calculated
- The relationships between different data dimensions
- The business logic behind aggregations and transformations
- The visual hierarchy and organization of information
While traditional BI tools usually hide these relationships in opaque UI configurations, code-based definitions make them machine-readable and learnable. The metrics layer becomes a natural extension, where business definitions are codified consistently and versionable, creating the foundation for an AI model to understand the business context. This enables automation and the generation of visualization.
This is why declarative is a prerequisite to GenBI. While AI can control visual interfaces, this approach is inefficient for complex business logic. The data model joins, metric aggregations and bus matrix require explicit declarations that AI can parse and understand; print-screened images are not enough.
How Would a GenBI Workflow Look Like?
BI-as-code enables GenBI workflows. A potential workflow would involve a GitHub PR based on a GitHub repo as the persistence layer, where humans and AI brainstorm.
Considering the initial flow chart, where humans could create the prompt within a PR, the model generates its artifacts and commits to it. The human analyzes, verifies, and iterates on the prompt until he is happy. When finished, he approves and merges the PR, which will be deployed to production.
This would allow for an excellent review stage, during which humans and AI can iterate with a persistent store on GitHub. This could work for visualizations (dashboards), business logic (metrics layer), and data models (DDL for data warehouses).
This cycle is similar to the Master Data Management process
In MDM, a person always approves the process. With AI, we validate the AI's generated code instead of human code or data. Human-in-the-Loop Data Analysis (HILDA) approaches, which emphasize end-to-end systems and foster data-centric communities, support this human-AI collaborative approach to data management.
From Conceptual to Physical Data Model
If we zoom out, we can use GenBI to model the conceptual to the physical layer, top-down.

Mapping each stage to a BI artifact, with GenBI's strength being more to the left, simply because we will have more context:
- Conceptual = Dashboard generation
- Logical = Metrics layer modeling
- Physical = Table and Joins (FKs) modeling
Core Components and Architecture
If we look at the landscape of GenBI, it's not yet well defined. Below is an attempt to highlight the different components that interact with each other in greater detail to achieve GenBI.

The most critical core components of GenBI are:
- Business Intelligence: BI-as-Code tool at the center and interface for human interactions. Declarative dashboards are stored with BI-as-Code and integrated with the metrics layer. The metrics layer serves as a repository of business definitions, including measures and data model relationships (joins, star/snowflake schema). Together with the declarative dashboards and metrics, they provide essential semantic context back to the AI engine for generating and modifying BI artifacts.
- GenBI Core: Consists of three key components working together
- Natural Language Interface: Enables human-like interaction with the system
- AI Engine: Processes queries and understands the business context
- BI-as-Code Generator: Transforms AI understanding into concrete, declarative code artifacts like YAML dashboard definitions and metrics configurations
- External Knowledge: Combines general knowledge from external LLMs with business-specific context through RAG (Retrieval-Augmented Generation). While LLMs provide a broad understanding, the RAG store enriches this with internal documents, legacy code, and company-specific data models.
- Data Sources: Serve as the foundation where the BI-as-Code Generator queries to validate and execute the generated artifacts against actual data. Represents any kind of database or files.
Key Components for Successful GenBI
To make BI successful, it needs to provide an instant overview of company performance to allow the leadership to make critical decisions fast. BI should boost data efficiency by automating repetitive tasks across the organization, such as updating daily active users and sending them to relevant stakeholders.
To achieve successful GenBI, we need to highlight at least two main components that need to be well integrated into GenAI to make BI successful:
- Dashboards: Quickly visualize the hard work of data engineers, the ingestion, wrangling, cleaning, and transforming of the data pipeline for the business and users.
Metrics Layer: Auto-generate definitions for standard metrics like monthly active users, year-to-date revenue, etc.
If we can further automate this process, we will overcome one of the biggest problems of BI: the bottleneck of the data or BI teams to ship or publish data artifacts. Also, the BI stack usually requires skills different from those of a domain expert. We have won a lot if it empowers domain experts who understand the business, how it runs, and how to present the numbers to tell a story.
You need to understand the company and its operations and know how to present the numbers in a way that tells a story.
This is usually where technical data professionals care least, so a trained model that helps us would significantly boost productivity. This is precisely where GenBI helps address these challenges.
Presentation Layer: Dashboards
Dashboards in GenBI serve as the primary interface between business insights and decision-makers. The iterative nature of dashboard development makes them particularly well-suited for AI assistance, with two distinct phases:
The initial creation process focuses on rapidly transforming business requirements into visualizations. GenBI excels here by understanding the context from the metrics layer and suggesting appropriate visualizations based on data characteristics and best practices.
GenBI truly shines in the iterative process of incorporating new features or data into the dashboard. It can provide feedback quickly, suggest improvements, and adapt visualizations based on user needs and data patterns. As dashboards are never truly finished, GenBI is an invaluable partner in continuous refinement, helping maintain consistency while reducing technical overhead.
Beautiful Visualization
Effective data visualization often produces clarity through simplicity rather than complexity. Methodologies such as Hichert SUCCESS Rules , Stephen Few's Information Dashboard Design, the works of Edward Tufte for business reporting. Key principles include:
- Use color strategically and sparingly
- Emphasize important data through selective highlighting
- Choose appropriate chart types for your data
- Employ direct labeling when possible
- Consider small multiples for complex comparisons
The Power of the Metrics Layer
The metrics layer serves as GenBI's semantic foundation, providing a declarative way to define and maintain core business definitions, including measures and data model relationships. GenBI creates a single source of truth that both humans and AI models can understand by centralizing these definitions in code. This is essential for consistently interpreting business logic across the organization, from simple metrics to complex star/snowflake schema relationships.
Beyond basic measure definitions, the metrics layer captures the semantic relationships between business concepts through explicit data model definitions like joins and fact/dimension relationships. This structured context enables the AI engine to understand individual metrics and how they relate to each other and the underlying data model. This comprehensive semantic understanding creates a powerful foundation for the AI engine when combined with declarative dashboards from the BI-as-Code tool.
The engine can generate contextually appropriate visualizations, suggest relevant metrics for specific business questions, and understand complex business calculations and their relationships. It can even auto-generate new metric definitions based on existing patterns while validating generated artifacts against the actual data model, ensuring consistency and accuracy in the business intelligence layer.
High-Performance Analytics Backend
If I had to add a third candidate, it would be an ultra-fast OLAP query backend to produce useful BI and AI responses. Modern OLAP engines like ClickHouse, Druid, Cube, and DuckDB provide the necessary speed and efficiency to handle complex analytical queries in real time, ensuring that GenBI systems can maintain interactive response times even when processing large datasets.
This performance capability is crucial for maintaining a fluid conversation between the users and the GenBI system. It allows for rapid iteration and refinement of analyses without interrupting the natural flow of exploration.
GenBI in Action
Let's examine GenBI's practical implications through example prompts. Later, we will look at an actual implementation with Rill.
Prompts for Dashboard Creation
Let's start with the user perspective and the prompts. Below are typical natural language requests (whether written or spoken) on how to "prompt engineer" a beautiful, fully functional dashboard. These prompts range from simple to advanced to interactive use cases that GenBI can help us with.
From simple metrics and visualizations:
Create a metric for revenue based on data in my ORDERS table.
Create a chart showing order revenue broken down by product category in the last year.
Create a visualization of revenue to sales goal this month, and set the sales goal at $28,283.
To more formatting and style update refinements:
Optimize for a cleaner visual aesthetic based on Edward Tufte's design guidelines.
Update on-brand color palette for this visualization based on the colors from our logo (upload logo).
Create more advanced dashboards with a specific focus:
Create a cohort analysis dashboard showing customer retention rates over 12 months, with the ability to filter by acquisition channel and highlight cohorts that exceeded 80% retention.
Build a drill-down capable sales dashboard that starts with global performance but allows users to click through to regional, store, and individual product level metrics, maintaining consistent visual language throughout the hierarchy.
Moving beyond basic visualizations, you can iteratively refine dashboards:
- Add a detailed table below the main "trend chart" showing monthly breakdowns
- Update the color scheme to use black for current year data and gray for previous year comparisons
- Add sparklines to the table columns showing 6-month trends
- Enable drill-down on product categories to show individual SKU performance
- Add conditional formatting to highlight values that are >10% below target in red
- Create a collapsible section for additional metrics like margin and inventory turnover
- Add hover tooltips showing YoY growth percentages
These are examples of prompt dashboards. Let's look at metric-specific generations.
Prompts for Metrics Generation
Exclude all refunds and returns from my revenue metric.
From basic metric definitions:
Create a metric for total revenue as the sum of order prices, define monthly active users based on our users table and calculate the average order value from our orders table
Generate star-schema data model metrics based on source DDL:
Analyze my source tables DDLs from Stripe (payments, subscriptions, customers), SAP (orders, inventory, suppliers), and our CRM (interactions, support_tickets) to create a consolidated dimensional model. Generate appropriate fact and dimension tables, define key metrics like revenue, customer lifetime value, and order frequency, and include common aggregations and filters.
Iterative refinement through conversation:
Human: "Create a revenue metric from our subscription and one-time payments"
GenBI: "How about:SUM(CASE WHEN type = 'subscription' THEN mrr * months ELSE amount END)"
Human: "Good, but we need to handle refnds and currencies" GenBI: "Updated to:SUM( CASE WHEN type = 'subscription' THEN mrr * months ELSE amount END * exchange_rate ) FILTER (WHERE status != 'refunded')"
Human: "Perfect, add it to the metrics layer asnet_revenue"
These examples showcase the range from simple aggregations to complex business logic while highlighting the conversational nature of GenBI and its ability to understand and implement business requirements iteratively.
Practical Implementation with Rill Developer
Today, Rill Developer uses GenAI to create dashboards or metrics based on your data sources or models. It also stores all your sources, models (SQL queries), and dashboards in YAML and has a live editor for visually changing them.
You can right-click on your model to use AI with the comfort of your BI tools (this works in the OSS and Cloud version):
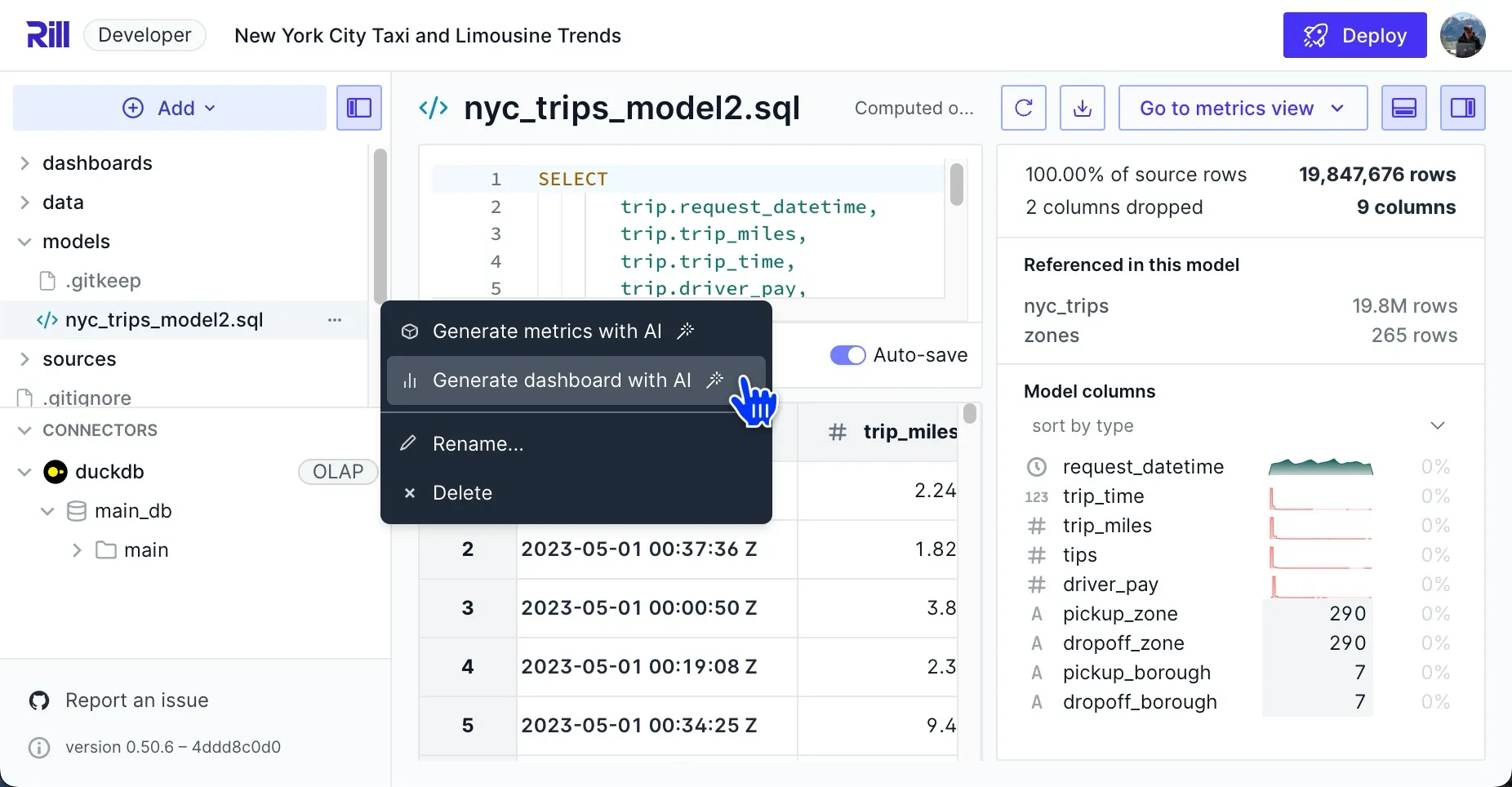
If you click, generate dashboard, that would look like this based on the infamous NYC taxi data set. Notice the beautiful pivot table at the end:
%2520copy%25202.gif)
This implementation demonstrates the future of one-click dashboards with generative AI, where LLMs like GPT can generate and modify dashboard definitions directly in code.
Rill’s BI-as-code philosophy means dashboards are defined entirely in code and that large language models, like OpenAI’s GPT series, can generate based on these definitions. Rill today does an OpenAI call to get domain-specific understanding, e.g., if the data model is a certain industry.
Incorporating code generation into development environments makes the tool much more user-friendly and can significantly improve a single BI engineer's productivity. Rill Developer also provides software engineers with a fast feedback loop, enabling them to edit code rapidly, visualize metrics, and instantly preview dashboards before deploying them into Rill Cloud or a self-managed environment.
What else does Rill Developer bring to the table? Rill is a CLI-first BI tool installed with a single command, opening up all kinds of new use cases, like embedding a complete GenBI tool as part of your data pipeline. Compared to traditional BI tools, that won't be possible any time soon. With that and its declarative approach, its integrations in the most common OLAP engines and common sources meet all GenBI requirements.
Get Started with Rill Developer and GenBI today
One-line installation:
curl https://rill.sh | shTo run a sample project, run now - select a project from the UI or add your data.
rill start my-rill-projectCheck out the Quick Start for more information.
Future of GenBI
After seeing what GenBI is, I understand the evolution from traditional BI to GenAI, using BI-as-Code as the foundation to enable powerful AI use cases that generate full dashboards and metrics based on existing data sources. We've seen the core components GenBI needs and how GenBI looks in action, both from the user perspective with prompts and from the implementation side with actual products that have implemented GenBI. For businesses, this means faster time-to-insight and democratized access to data analytics without sacrificing the robustness of traditional BI approaches.
So, what's the future of GenBI? While this is difficult to predict, I'm confident Rill Developer will be at the forefront, enabling users with simple business requirements to access the entire BI stack—maybe even beyond. In the following article, we'll look at how a declarative data stack could be implemented, integrating the BI part and end-to-end what we discussed in Part 1 and the Rise of the Declarative Data Stack.
.jpg)
.svg)



Ready for faster dashboards?
Try for free today.